Soil Analysis Record Database Design
Introduction
Table of Contents
Managing soil analysis records is essential for agricultural professionals, researchers, and environmental scientists. This tutorial will guide you through designing an efficient database system for storing, organizing, and accessing soil analysis data.
Purpose of the Tutorial
The goal of this tutorial is to provide a clear, step-by-step guide for creating a Soil Analysis Record Management System. By the end of this tutorial, you will have a complete database design that is easy to implement and capable of handling complex soil analysis data efficiently.
Overview of Soil Analysis Record Management
Soil analysis involves testing soil samples for various parameters such as pH, nutrient content, and moisture levels. These tests are crucial for understanding soil health and making informed decisions in agriculture, land management, and environmental conservation. With a well-designed database, you can track soil samples, store test results, and generate comprehensive reports—all in one place.
Importance of a Well-Structured Database
A well-structured database is the backbone of effective data management. It ensures data integrity, reduces redundancy, and makes it easy to retrieve and analyze information. For soil analysis, a robust database can help you manage large volumes of data, track sample histories, and provide valuable insights for improving soil health and productivity.
In this tutorial, we’ll start by designing a database schema tailored for soil analysis record management, covering everything from soil sample collection to lab test results and final reporting. Let’s get started!
Database Design Basics
Creating an efficient database design is crucial for managing and organizing data effectively. In this section, we’ll cover the fundamental concepts of databases, including tables, data types, keys, and normalization. Understanding these basics will set the foundation for building a robust Soil Analysis Record Management System.
Concepts of Databases and Tables
A database is a structured collection of data stored and managed electronically. It organizes information in a way that makes it easy to retrieve, update, and manage. A database consists of tables, which are like spreadsheets with rows and columns. Each table stores data about a specific entity, such as soil samples, test parameters, or laboratories.
For example, in our soil analysis system, we would have tables like tbl_sample for storing soil sample data and tbl_test_parameter for the types of tests conducted.
Data Types and Their Usage
Each column in a table must be assigned a data type that defines the kind of data it can store. Choosing the right data type is important for data integrity and efficient storage. Common data types include:
- Integer: Whole numbers, used for IDs or counts (e.g., sample_id).
- Varchar: Variable-length strings, used for text entries like names or descriptions (e.g., soil_type_name).
- Date: Dates, used for storing dates of events (e.g., date_collected).
- Decimal: Numbers with decimal points, used for precise values (e.g., test results like pH).
Selecting appropriate data types ensures that each column stores data efficiently and accurately.
Primary Keys and Foreign Keys
Primary keys uniquely identify each record in a table. They are crucial for maintaining data integrity and ensuring that each row is distinct. For example, sample_id in the tbl_sample table is a primary key, as it uniquely identifies each soil sample.
Foreign keys establish relationships between tables. They refer to the primary key in another table and link related data. For example, in the tbl_analysis_result table, sample_id is a foreign key that connects to the sample_id in the tbl_sample table, linking each test result to a specific soil sample.
Using primary and foreign keys ensures consistent relationships between your tables, making your data reliable and easy to query.
Normalization and Its Benefits
Normalization is the process of organizing a database to reduce redundancy and improve data integrity. It involves dividing large tables into smaller, related ones and defining relationships between them.
The benefits of normalization include:
- Eliminating Data Redundancy: Data is stored only once, reducing storage space and preventing inconsistencies.
- Improving Data Integrity: Each piece of information is stored in a specific table, minimizing the risk of data anomalies.
- Efficient Data Management: Normalized databases are easier to maintain and update, ensuring that changes in one part of the database are reflected across all related data.
For example, instead of storing soil type details repeatedly in every sample record, we use a separate tbl_soil_type table and link it with soil_type_id. This setup not only saves space but also simplifies updates to soil type information.
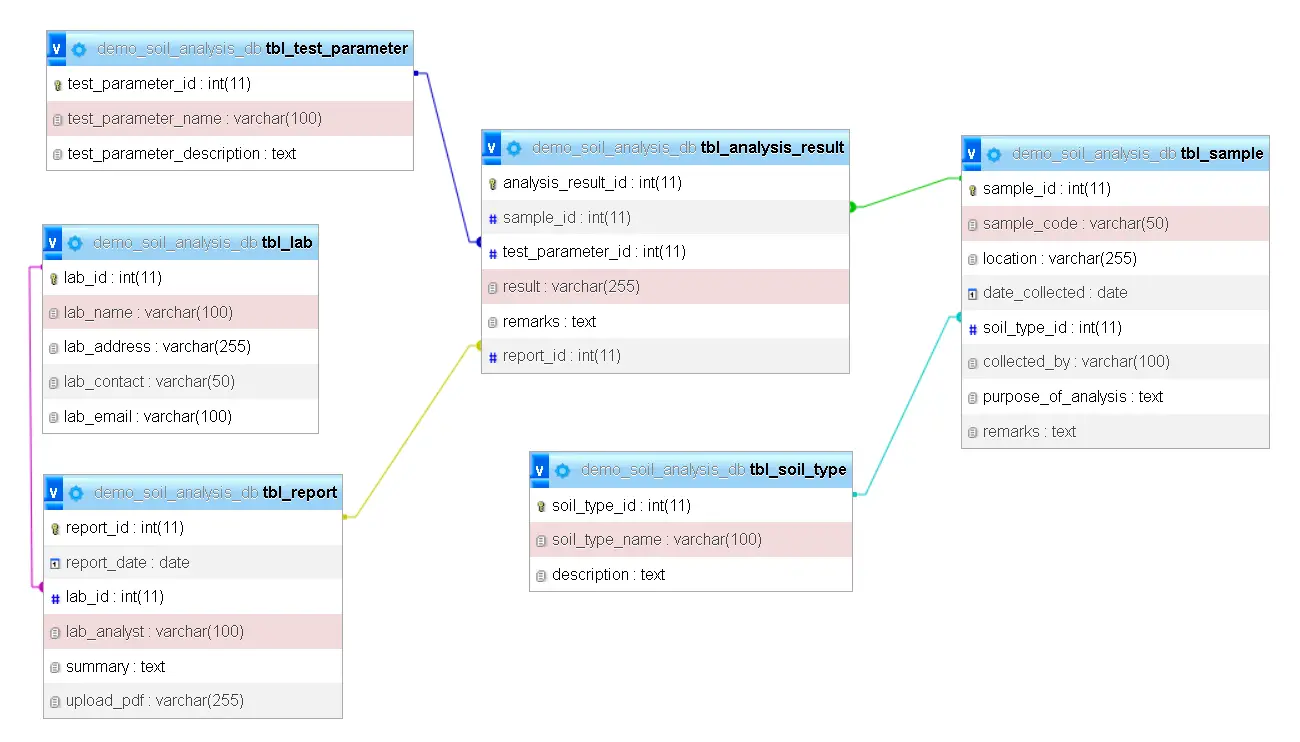
Explanation of Each Table
In a Soil Analysis Record Management System, each table serves a distinct purpose and helps in organizing data efficiently. Here’s a detailed explanation of each table in the design:
- tbl_soil_type
This table stores information about different soil types. It helps in categorizing and identifying the soil samples based on their types.
- Columns:
- soil_type_id: Unique identifier for each soil type (Primary Key).
- soil_type_name: Name of the soil type (e.g., Clay, Loam).
- description: A brief description of the soil type and its characteristics.
- tbl_sample
This table contains data about the soil samples collected for analysis. Each record corresponds to a specific sample and includes details such as collection location and purpose.
- Columns:
- sample_id: Unique identifier for each soil sample (Primary Key).
- sample_code: A code assigned to the sample for tracking.
- location: The location where the sample was collected.
- date_collected: The date when the sample was collected.
- soil_type_id: References tbl_soil_type to indicate the type of soil (Foreign Key).
- collected_by: Name of the person who collected the sample.
- purpose_of_analysis: Reason for analyzing the sample (e.g., agricultural suitability).
- remarks: Additional notes or observations about the sample.
- tbl_lab
This table stores information about laboratories where soil analyses are conducted. It is essential for tracking which lab performed specific tests.
- Columns:
- lab_id: Unique identifier for each laboratory (Primary Key).
- lab_name: Name of the laboratory.
- lab_address: Address of the laboratory.
- lab_contact: Contact number for the laboratory.
- lab_email: Email address of the laboratory.
- tbl_test_parameter
This table defines the different test parameters used for soil analysis, such as pH levels, nutrient content, and more.
- Columns:
- test_parameter_id: Unique identifier for each test parameter (Primary Key).
- test_parameter_name: Name of the test parameter (e.g., pH, Nitrogen Content).
- test_parameter_description: Description of the test parameter and its significance.
- tbl_analysis_result
This table records the results of the tests performed on each soil sample. Each entry links a specific sample and test parameter to a result.
- Columns:
- analysis_result_id: Unique identifier for each analysis result (Primary Key).
- sample_id: References tbl_sample to indicate which sample was tested (Foreign Key).
- test_parameter_id: References tbl_test_parameter to indicate which test was conducted (Foreign Key).
- result: The result of the test (e.g., pH level of 6.5).
- remarks: Additional comments or notes on the result.
- report_id: References tbl_report to link the result to a specific report (Foreign Key).
- tbl_report
This table contains information about generated reports, which include summaries of the analysis and any related documentation.
- Columns:
- report_id: Unique identifier for each report (Primary Key).
- report_date: Date the report was generated.
- lab_id: References tbl_lab to indicate which lab generated the report (Foreign Key).
- lab_analyst: Name of the lab analyst who prepared the report.
- summary: A summary of the findings in the report.
- upload_pdf: A link or path to the uploaded PDF version of the report.
This database design provides a comprehensive framework for managing soil analysis data. By organizing information into these distinct tables, you can easily track soil samples, store detailed test results, and generate meaningful reports. Each table is interconnected through keys, allowing for efficient data retrieval and analysis, ensuring that the system is both scalable and easy to maintain.
SQL Statement
-- Table: tbl_soil_type CREATE TABLE tbl_soil_type ( soil_type_id INT AUTO_INCREMENT PRIMARY KEY, soil_type_name VARCHAR(100) NOT NULL, description TEXT ); -- Table: tbl_lab CREATE TABLE tbl_lab ( lab_id INT AUTO_INCREMENT PRIMARY KEY, lab_name VARCHAR(100) NOT NULL, lab_address VARCHAR(255), lab_contact VARCHAR(50), lab_email VARCHAR(100) ); -- Table: tbl_report CREATE TABLE tbl_report ( report_id INT AUTO_INCREMENT PRIMARY KEY, report_date DATE NOT NULL, lab_id INT, lab_analyst VARCHAR(100), summary TEXT, upload_pdf VARCHAR(255), FOREIGN KEY (lab_id) REFERENCES tbl_lab(lab_id) ); -- Table: tbl_test_parameter CREATE TABLE tbl_test_parameter ( test_parameter_id INT AUTO_INCREMENT PRIMARY KEY, test_parameter_name VARCHAR(100) NOT NULL, test_parameter_description TEXT ); -- Table: tbl_sample CREATE TABLE tbl_sample ( sample_id INT AUTO_INCREMENT PRIMARY KEY, sample_code VARCHAR(50) NOT NULL, location VARCHAR(255) NOT NULL, date_collected DATE NOT NULL, soil_type_id INT, collected_by VARCHAR(100), purpose_of_analysis TEXT, remarks TEXT, FOREIGN KEY (soil_type_id) REFERENCES tbl_soil_type(soil_type_id) ); -- Table: tbl_analysis_result CREATE TABLE tbl_analysis_result ( analysis_result_id INT AUTO_INCREMENT PRIMARY KEY, sample_id INT, test_parameter_id INT, result VARCHAR(255) NOT NULL, remarks TEXT, report_id INT, FOREIGN KEY (sample_id) REFERENCES tbl_sample(sample_id), FOREIGN KEY (test_parameter_id) REFERENCES tbl_test_parameter(test_parameter_id), FOREIGN KEY (report_id) REFERENCES tbl_report(report_id) );
Summary:
- tbl_lab is created before tbl_report so that tbl_report can reference it.
- tbl_report is created before tbl_analysis_result so that tbl_analysis_result can reference it.
- tbl_test_parameter and tbl_soil_type are created before tbl_sample and tbl_analysis_result to ensure that the foreign keys can be properly referenced.
Relationships
In the Soil Analysis Record Management System, the tables are interrelated through primary and foreign keys, allowing for structured data storage and efficient retrieval. Let’s go through the relationships among these tables:
- tbl_soil_type ↔ tbl_sample
- Relationship: One-to-Many
- Explanation: Each soil type can be associated with multiple soil samples, but each sample can only have one soil type.
- Foreign Key: The soil_type_id in tbl_sample references the soil_type_id in tbl_soil_type.
- Example: If a soil type named “Clay” has an ID of 1, multiple samples collected from different locations that are identified as “Clay” will reference this ID in their soil_type_id column.
- tbl_sample ↔ tbl_analysis_result
- Relationship: One-to-Many
- Explanation: A single soil sample can undergo multiple tests, resulting in multiple entries in the analysis results table. Each analysis result is linked to only one sample.
- Foreign Key: The sample_id in tbl_analysis_result references the sample_id in tbl_sample.
- Example: A soil sample collected at a specific location may be tested for pH, nitrogen content, and potassium levels, generating separate results for each test in tbl_analysis_result.
- tbl_test_parameter ↔ tbl_analysis_result
- Relationship: One-to-Many
- Explanation: Each test parameter, such as pH or nitrogen content, can be used in multiple analysis results, but each result refers to only one test parameter.
- Foreign Key: The test_parameter_id in tbl_analysis_result references the test_parameter_id in tbl_test_parameter.
- Example: The test parameter “pH” might be used in several samples. Each time a pH test is conducted, a new result entry in tbl_analysis_result will link to the same test_parameter_id for pH.
- tbl_lab ↔ tbl_report
- Relationship: One-to-Many
- Explanation: A single laboratory can generate multiple reports, but each report is associated with only one lab.
- Foreign Key: The lab_id in tbl_report references the lab_id in tbl_lab.
- Example: If a lab named “ABC Lab” has an ID of 1, all reports generated by this lab will have lab_id = 1 in the tbl_report table.
- tbl_sample ↔ tbl_report (via tbl_analysis_result)
- Relationship: Indirect One-to-Many
- Explanation: A single report can include analysis results from multiple samples. This relationship is established through the tbl_analysis_result table, which connects each sample to a specific report.
- Foreign Key: The report_id in tbl_analysis_result references the report_id in tbl_report.
- Example: A report summarizing the results of various tests will reference multiple sample_id values via the tbl_analysis_result table.
Summary of Relationships
- One-to-Many Relationships:
- tbl_soil_type ↔ tbl_sample: One soil type has many samples.
- tbl_sample ↔ tbl_analysis_result: One sample has many test results.
- tbl_test_parameter ↔ tbl_analysis_result: One test parameter can be used in many results.
- tbl_lab ↔ tbl_report: One lab can generate multiple reports.
- Indirect Relationships:
- tbl_sample ↔ tbl_report (via tbl_analysis_result): Multiple samples can be associated with a single report through their test results.
These relationships ensure that the database maintains referential integrity, enabling robust data management and easy retrieval of related records across the system.
Conclusion
In this tutorial, we explored the core features and database design of a Soil Analysis Record Management System. We began by understanding the purpose of each table and how they relate to each other. The tbl_soil_type table defines the various types of soil, while tbl_sample records detailed information about collected soil samples. Laboratories where these samples are analyzed are documented in tbl_lab. The tbl_test_parameter table outlines the various tests that can be conducted on the samples. All analysis results are stored in tbl_analysis_result, and detailed reports summarizing these results are managed in tbl_report. The relationships among these tables ensure efficient data management and retrieval, forming a cohesive structure that supports comprehensive soil analysis records.
Future Enhancements:
To further enhance the functionality of the Soil Analysis Record Management System, consider implementing the following features:
- Automated Notifications: Set up automated email or SMS notifications to alert users when lab results are available or when specific soil tests have been completed. This can improve communication and workflow efficiency.
- Integration with GIS Systems: Integrate the system with Geographic Information Systems (GIS) to visualize sample collection locations and generate geographical reports.
- Advanced Reporting and Analytics: Develop more sophisticated reporting tools that allow users to generate custom reports based on various criteria, such as soil type, location, or date range.
- User Access and Permissions: Implement user roles and permissions to ensure secure access to sensitive data and allow different user groups to perform specific actions within the system.
- Integration with External Systems: Enable integration with external laboratory information management systems (LIMS) to automatically import test results and reduce manual data entry.
These enhancements can significantly increase the usability and value of the Soil Analysis Record Management System, making it a more powerful tool for soil data management and analysis.
You may visit our Facebook page for more information, inquiries, and comments. Please subscribe also to our YouTube Channel to receive free capstone projects resources and computer programming tutorials.
Hire our team to do the project.